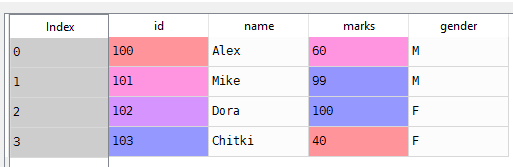
List of students in a class with marks
# List of students with marks in mathematics subject
students = [(100, 'Alex', 60, 'M'), (101, 'Mike', 99, 'M'), (102, 'Dora', 100, 'F'), (103, 'Chitki', 40, 'F')]
# Create a data frame from list of tuples
df = pd.DataFrame.from_records(students, columns=['id', 'name', 'marks', 'gender'])
# Group student by Gender column
grouped_data = df.groupby('gender')
# Know the type of grouped data
type(grouped_data)
>>>
pandas.core.groupby.DataFrameGroupBy
``
Display students grouped by gender
```Python
# iterate through group by data frame
for gender, group_df in grouped_data:
print(gender)
print(group_df)
>>>
F
id name marks gender
2 102 Dora 100 F
3 103 Chitki 40 F
M
id name marks gender
0 100 Alex 60 M
1 101 Mike 99 MGet maximum marks in male
grouped_data.get_group('M')['marks'].max()
>>>
99
# Using aggregate function and pass numpy max function as argument
grouped_data.get_group('M')['marks'].agg(np.max)
>>
99Prefer to use numpy functions because we will get performance improvement
Lets add one mark to all the students using normal way or transform method`
# Lets add one mark to all the students
df['marks'] = df['marks'] + 1
# define an increment function
def increment(marks):
return marks + 1
# Apply the increment method to marks column
df['marks'].transform(increment)